Over 700 Earth observation satellites are orbiting our planet, transmitting hundreds of terabytes of data to downlink stations every day. Processing and extracting useful information is a huge data challenge, with volumes rising quasi-exponentially.
And, it’s not just a problem of the data deluge: our climate system, and environmental processes more widely, work in complex and non-linear ways. Artificial intelligence and, in particular, machine learning is helping to meet these challenges, as the need for accurate knowledge about global climate change becomes more urgent.
ESA’s Climate Change Initiative provides the systematic information needed by the UN Framework Convention on Climate Change. By funding teams of scientists to create world-class accurate, long-term, datasets that characterise Earth’s changing climate system, the initiative is providing a whole-globe view.
Derived from satellites, these datasets cover 21 ‘essential climate variables’, from greenhouse gas concentrations to sea levels and the changing state of our polar ice sheets. Spanning four decades, these empirical records underpin the global climate models that help predict future change.
A book from 1984 – Künstliche Intelligenz by E.D. Schmitter – bears testimony to Carsten Brockmann’s long interest in artificial intelligence. Today he is applying this knowledge at an ever-increasing pace to his other interest, climate change.
“What was theoretical back then is now becoming best practice,” says Dr Brockmann who believes artificial intelligence has the power to address pressing challenges facing climate researchers.
Artificial intelligence algorithms – computer systems that learn and act in response to their environment – can improve detection rates in Earth observation. For example, it is common to use the ‘random forests’ algorithm, which uses a training dataset to learn to detect different land-cover types or areas burnt by wildfires. In machine learning, computer algorithms are trained, in the statistical sense, to split, sort and transform data to improve dataset classification, prediction, or pattern discovery.
Dr Brockmann says, “Connections between different variables in a dataset are caused by the underlying physics or chemistry, but if you tried to invert the mathematics, often too much is unknown, and so unsolvable.
“For humans it’s often hard to find connections or make predictions from these complex and nonlinear climate data.”
Artificial intelligence helps by building up connections automatically. Exposing the data to artificial intelligence methods enables the algorithms to ‘play’ with data and find statistical connections. These ‘convolutional neural network’ algorithms have the potential to resolve climate science problems that vary in space and time.
For example, in Climate Change Initiative scientists in the Aerosol project need to determine changes in reflected sunlight owing to the presence of dust, smoke and pollution in the atmosphere, called aerosol optical depth.
Thomas Popp, who is science leader for the project, thinks there could be further benefits by using artificial intelligence to retrieve additional aerosol parameters, such as their composition or absorption from several sensors at once. “I want to combine several different satellite instruments and do one retrieval. This would mean gathering aerosol measurements across visible, thermal and the ultraviolet spectral range, from sensors with different viewing angles.”
He says solving this as a big data problem could make these data automatically fit together and be consistent.
“Explainable artificial intelligence is another evolving area that could help unveil the physics or chemistry behind the data”, says Dr Brockmann, who is in the Climate Change Initiative’s Ocean Colour science team.
“In artificial intelligence, computer algorithms learn to deal with an input dataset to generate an output, but we don’t understand the hidden layers and connections in neural networks: the so-called black box.
“We can’t see what’s inside this black box, and even if we could, it wouldn’t tell us anything. In explainable artificial intelligence, techniques are being developed to shine a light into this black box to understand the physical connections.”
Dr Brockmann and Popp joined leading climate and artificial intelligence experts to explore how to fully exploit Earth observation data during ESA’s ɸ-week, which was held last week. Things have come a long way since Dr Brockmann bought his little book and he commented, “It was a very exciting week!”
The Industrial Revolution conjures up images of steam engines, textile mills, and iron workers. This was a defining period during the late 18th and early 19th centuries, as society shifted from primarily agrarian to factory-based work. A second phase of rapid industrialization occurred just before World War I, driven by growth in steel and oil production, and the emergence of electricity.
Fast-forward to the 1980s, when digital electronics started having a deep impact on society—the dawning Digital Revolution. Building on that era is what’s called the Fourth Industrial Revolution. Like its predecessors, it is centered on technological advancements—this time it’s artificial intelligence (AI), autonomous machines, and the internet of things—but now the focus is on how technology will affect society and humanity’s ability to communicate and remain connected.
“In the first Industrial Revolution, we replaced brawn with steam. In the second, we replaced steam with electricity, and in the third, we introduced computers,” says Guido Jouret, chief digital officer for Swiss industrial corporation ABB. “We’ve had intelligent rule-based systems. What we haven’t had is the equivalent of the human cortex—systems that can learn.”
That’s what AI technologies represent in the current period of technological change. It is now critical to carefully consider the future of AI, what it will look like, the effect it will have on human life, and what challenges and opportunities will arise as it evolves
What is holding up AI adoption, and where is it already in use?
Even early concerns related to artificial intelligence (AI) have not appeared to slow its adoption. Some companies are already seeing benefit and experts are saying companies not adopting new technology will not be able to compete over time. However, AI adoption seems to be moving slowly despite early successful case studies.
Why AI is Moving so Slow in Manufacturing?
AI is growing, but exact numbers can be difficult to obtain, as the definition of technologies such as machine learning, AI, machine vision, and others are often blurred. For example, using a robotic arm and camera to inspect parts might be advertised as a machine learning or an AI device. While the device could work well, it might only be comparing images taken to others that were manually added it to a library. Some would argue this is not a machine learning device as it is making a preprogrammed decision, not one “learned” from the machine’s experience.
Going forward, this article will use general terms when mentioning AI technology. But when deciding on a design or product, make sure you understand the differences between terms such as supervised vs. unsupervised, and other buzzwords that might get blurry through sales and marketing efforts.
According to a Global Market Insights report publish in February this year, the marketsize for AI in manufacturing is estimated to have surpassed $1 billion in 2018, and is anticipated to grow at a CAGR of more than 40% from 2019 to 2025. But other resources insist that AI is moving slower. Some resources are often comparing AI case studies to the entire size of the manufacturing market, talking about individual companies investments, or specifically AI on a mass scale. From this prospective, AI growth is slower, and that is for a few reasons other than the aforementioned.
AI is still a new technology. Much of the success has been in the form of testbeds, not full-scale projects. This is because in large companies, one small adjustment could affect billions of dollars, so managers don’t want to test full-scale projects until they’'ve found the best solution. Additionally, companies of any size need to justify or guarantee a return on investment (ROI). This leads to smaller projects, a focus on low-hanging fruit, or projects that can be isolated as a testbed.
The tool is used by 50,000 schoolchildren at 150 schools and one says it has helped decrease self-harm by 20%.
One of England's biggest academy chains is testing pupils' mental health using an AI (artificial intelligence) tool which can predict self-harm, drug abuse and eating disorders, Sky News can reveal.
A leading technology think tank has called the move "concerning", saying "mission creep" could mean the test is used to stream pupils and limit their educational potential.
The Academies Enterprise Trust has joined private schools such as Repton and St Paul's in using the tool, which tracks the mental health of students across an entire school and suggests interventions for teachers.
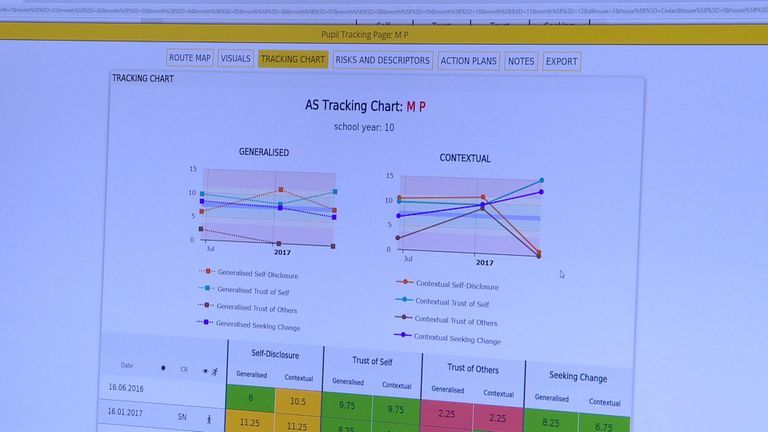
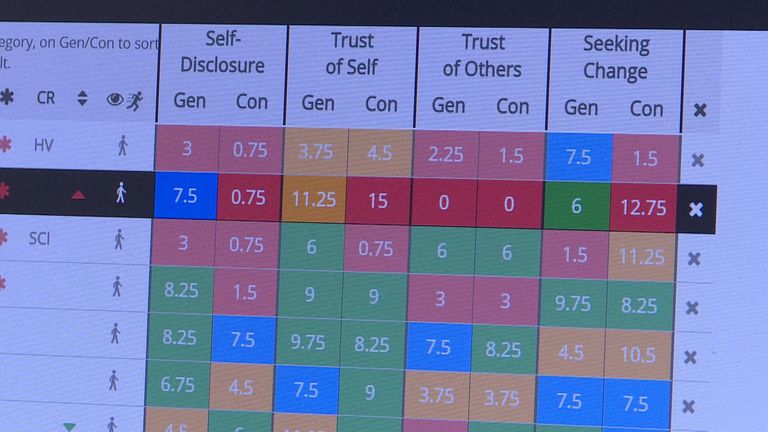
This month, 50,000 schoolchildren at 150 schools will take the online psychological test, called AS Tracking, including 10,000 Academies Enterprise Trust pupils.
Teachers say use of the tool is "snowballing" as it offers a way to ease the pressure on teenagers struggling to deal with social media scrutiny and academic stress.
The test, which is taken twice a year, asks students to imagine a space they feel comfortable in, then poses a series of abstract questions, such as "how easy is it for somebody to come into your space?"
The child can then respond by clicking a button on a scale that runs from "very easy" to "very difficult"
Dr Simon Walker, a cognitive scientist who conducted studies with 10,000 students in order to develop AS Tracking, says this allows teachers to hear pupils' "hidden voice" - in contrast to traditional surveys, which tend to ask more direct questions.
"A 13-year-old girl or boy isn't going to tell a teacher whether they're feeling popular or thinking about self harm, so getting reliable information is very difficult," he says.
Once a child has finished the questionnaire, the results are sent to STEER, the company behind AS Tracking, which compares the data with its psychological model, then flags students which need attention in its teacher dashboard.
"Our tool highlights those particular children who are struggling at this particular phase of their development and it points the teachers to how that child is thinking," says STEER co-founder Dr Jo Walker.
Education is an ancient sector of our economy that has largely remained unchanged.
Artificial Intelligence and machine learning have disrupted human activity since its inception in the 1960s. Today, we depend on intelligent machines to perform highly sophisticated and specific tasks without explicit human input. Rather, they rely on patterns and inferences instead. AI algorithms have been used in a wide variety of applications, from email filtering and computer vision to the disruption of the retail, travel and finance industries.
An ancient sector of our economy, and one that has largely remained unchanged; education- has yet to realise the full implications of artificial intelligence within its operations. Until recently, university students are taught via a ‘one module fits all’ structure, within the confines of a classroom, with very little personal and individually constructed development procedures.
Resultantly, our current model of higher education has produced, on the whole, an unspecialised and underutilised workforce. Such a workforce entering into an increasingly digital world economy or artificial intelligence and machine learning has been somewhat incompatible.
It’s only a matter of time before artificial intelligence creeps into the realms of higher education and transforms the way we teach, learn, work and live. In fact, AI has been applied to the functioning of some educational establishments in an effort to provide opportunities for professional development in an increasingly digitised world.
University 20.35 pioneers an entirely new university model, where each student at any given moment makes a decision based on recommendations that take into account his or her digital footprint, that of other students, and the educational content that’s available to them. Such recommendations include; the choice of professional development, the skills necessary for the profession, a selection of courses, events and activities that will help to secure the student's professional development.
Each student's digital footprint can be collected during education processes to confirm the student's skills. From here, gaps in knowledge are detected and it confirms that a trajectory module tutor is able to efficiently transfer skills to students. This transfer is based on the students' existing skills analysis, educational background and habits. Essentially, it holds the capacity for impeccable efficiency gains.
The collection of Big Data and its analysis of students’ professional and educational allows the university to tailor the education path to the student.
These AI modified educational processes have the capacity to generate what would be the students ‘digital twin’. In many ways, our digital twin already exists. The social media we use are all collecting parts of ‘our self’, likewise; governments, healthcare systems and retail companies are too collecting fragments of us.
Whether it’s data on our shopping preferences, or data representing our skills as employees. The education system, at the very least, can collect records in what we have learnt.
An educational digital twin is the replica of the students own physical profile, this almost real-time digital replica of the student's progress can illustrate student’s skills and knowledge. It can also be modelled to take into account the things we forget, and the skills we are practising. It is this information of our fluctuating (diminishing & strengthening) knowledge, that can be a starting point for an intelligent, proactive educational program.
In other words, AI technology should allow us to aggregate those fragments of ourselves into a more comprehensive one that better represents us. It’s worth noting for clarification that through our searches, Google has come to know us quite well. So, it has a fairly good representation of our interests - which to some extent reflects who we are. Based on these reflections, Google often recommends content, news, stories and websites that might interest you further.
Artificial intelligence has the capacity to introduce personalised learning to the extraordinarily generic syllabus that exists today. AI gives students personal development pathways based on their digital footprint. In other words, AI can more accurately than humans, draw out the students skills and capabilities, which should be developed and enhanced. As a result of this model of learning, the future of the digital economy can anticipate a more refined and expert workforce.
As educational AI develops, students are going to be able to study where and when they want, using whichever system/platform that suits them. This is likely to result in tablets, mobile devices and other personal devices becoming the main delivery modes of education. The traditional classroom setups are forecast to move towards a more interactive style of working. Subsequently, this will contribute to the gathering and circulating of big data. As such, the use of AI in monitoring students digital footprint to aid personalised study programs will reach new levels of proficiency.
Collaboration on the blockchain
Another dimension of using AI innovations in universities will be implementing the use of blockchain technology. This will revolutionise the way universities operate and will welcome institutions to share and collaborate with each other securely.
The international digital ecosystem heavily depends on the inclusion of universities contributing to the building and maintenance of that system. Through developing sound data-driven management, constant renewal of the educational program’s core based on students’ reactions, digitalisation of the environment that requires new skills, and fruitful collaboration across universities.
In the 1960s and 1970s, pursuing higher education was a minority choice. By 2018, more than 2.3 million students had enrolled at higher education institutions in the UK alone. As with the changing demographics of university students, the economy has changed drastically too. A saturated workforce and an economy making continuous digital progress has the potential to thrive- but only with specialised and proficient personnel.
The education process using artificial intelligence is expected to produce a different calibre of skilled students, thus reinstating institution credibility. The number of university students can therefore increase, whilst simultaneously producing a higher number of specialised graduates.
Probability is a field of mathematics that quantifies uncertainty.
It is undeniably a pillar of the field of machine learning, and many recommend it as a prerequisite subject to study prior to getting started. This is misleading advice, as probability makes more sense to a practitioner once they have the context of the applied machine learning process in which to interpret it.
In this post, you will discover why machine learning practitioners should study probabilities to improve their skills and capabilities.
After reading this post, you will know:
Not everyone should learn probability; it depends where you are in your journey of learning machine learning.
Many algorithms are designed using the tools and techniques from probability, such as Naive Bayes and Probabilistic Graphical Models.
The maximum likelihood framework that underlies the training of many machine learning algorithms comes from the field of probability.
Discover bayes opimization, naive bayes, maximum likelihood, distributions, cross entropy, and much more in my new book, with 28 step-by-step tutorials and full Python source code.
Let’s get started.
5 Reasons to Learn Probability for Machine Learning Photo by Marco Verch, some rights reserved.
Overview
This tutorial is divided into seven parts; they are:
Reasons to NOT Learn Probability
Class Membership Requires Predicting a Probability
Some Algorithms Are Designed Using Probability
Models Are Trained Using a Probabilistic Framework
Models Can Be Tuned With a Probabilistic Framework
Probabilistic Measures Are Used to Evaluate Model Skill
One More Reason
Reasons to NOT Learn Probability
Before we go through the reasons that you should learn probability, let’s start off by taking a small look at the reason why you should not.
I think you should not study probability if you are just getting started with applied machine learning.
It’s not required. Having an appreciation for the abstract theory that underlies some machine learning algorithms is not required in order to use machine learning as a tool to solve problems.
It’s slow. Taking months to years to study an entire related field before starting machine learning will delay you achieving your goals of being able to work through predictive modeling problems.
It’s a huge field. Not all of probability is relevant to theoretical machine learning, let alone applied machine learning.
I recommend a breadth-first approach to getting started in applied machine learning.
I call this the results-first approach. It is where you start by learning and practicing the steps for working through a predictive modeling problem end-to-end (e.g. how to get results) with a tool (such as scikit-learn and Pandas in Python).
This process then provides the skeleton and context for progressively deepening your knowledge, such as how algorithms work and, eventually, the math that underlies them.
After you know how to work through a predictive modeling problem, let’s look at why you should deepen your understanding of probability.
1. Class Membership Requires Predicting a Probability
Classification predictive modeling problems are those where an example is assigned a given label.
An example that you may be familiar with is the iris flowers dataset where we have four measurements of a flower and the goal is to assign one of three different known species of iris flower to the observation.
We can model the problem as directly assigning a class label to each observation.
Input: Measurements of a flower.
Output: One iris species.
A more common approach is to frame the problem as a probabilistic class membership, where the probability of an observation belonging to each known class is predicted.
Input: Measurements of a flower.
Output: Probability of membership to each iris species.
Framing the problem as a prediction of class membership simplifies the modeling problem and makes it easier for a model to learn. It allows the model to capture ambiguity in the data, which allows a process downstream, such as the user to interpret the probabilities in the context of the domain.
The probabilities can be transformed into a crisp class label by choosing the class with the largest probability. The probabilities can also be scaled or transformed using a probability calibration process.
This choice of a class membership framing of the problem interpretation of the predictions made by the model requires a basic understanding of probability.
2. Some Algorithms Are Designed Using Probability
There are algorithms that are specifically designed to harness the tools and methods from probability.
These range from individual algorithms, like Naive Bayes algorithm, which is constructed using Bayes Theorem with some simplifying assumptions.
Naive Bayes
It also extends to whole fields of study, such as probabilistic graphical models, often called graphical models or PGM for short, and designed around Bayes Theorem.
Probabilistic Graphical Models
A notable graphical model is Bayesian Belief Networks or Bayes Nets, which are capable of capturing the conditional dependencies between variables.
Bayesian Belief Networks
3. Models Are Trained Using a Probabilistic Framework
Many machine learning models are trained using an iterative algorithm designed under a probabilistic framework.
Perhaps the most common is the framework of maximum likelihood estimation, sometimes shorted as MLE. This is a framework for estimating model parameters (e.g. weights) given observed data.
This is the framework that underlies the ordinary least squares estimate of a linear regression model.
The expectation-maximization algorithm, or EM for short, is an approach for maximum likelihood estimation often used for unsupervised data clustering, e.g. estimating k means for k clusters, also known as the k-Means clustering algorithm.
For models that predict class membership, maximum likelihood estimation provides the framework for minimizing the difference or divergence between an observed and predicted probability distribution. This is used in classification algorithms like logistic regression as well as deep learning neural networks.
It is common to measure this difference in probability distribution during training using entropy, e.g. via cross-entropy. Entropy, and differences between distributions measured via KL divergence, and cross-entropy are from the field of information theory that directly build upon probability theory. For example, entropy is calculated directly as the negative log of the probability.
4. Models Can Be Tuned With a Probabilistic Framework
It is common to tune the hyperparameters of a machine learning model, such as k for kNN or the learning rate in a neural network.
Typical approaches include grid searching ranges of hyperparameters or randomly sampling hyperparameter combinations.
Bayesian optimization is a more efficient to hyperparameter optimization that involves a directed search of the space of possible configurations based on those configurations that are most likely to result in better performance.
As its name suggests, the approach was devised from and harnesses Bayes Theorem when sampling the space of possible configurations.
5. Probabilistic Measures Are Used to Evaluate Model Skill
For those algorithms where a prediction of probabilities is made, evaluation measures are required to summarize the performance of the model.
There are many measures used to summarize the performance of a model based on predicted probabilities. Common examples include aggregate measures like log loss and Brier score.
For binary classification tasks where a single probability score is predicted, Receiver Operating Characteristic, or ROC, curves can be constructed to explore different cut-offs that can be used when interpreting the prediction that, in turn, result in different trade-offs. The area under the ROC curve, or ROC AUC, can also be calculated as an aggregate measure.
Choice and interpretation of these scoring methods require a foundational understanding of probability theory.
One More Reason
If I could give one more reason, it would be: Because it is fun.
Seriously.
Learning probability, at least the way I teach it with practical examples and executable code, is a lot of fun. Once you can see how the operations work on real data, it is hard to avoid developing a strong intuition for a subject that is often quite unintuitive.
Do you have more reasons why it is critical for an intermediate machine learning practitioner to learn probability?
Artificial intelligence is at the center of many emerging technologies today, and perhaps nowhere are the implications more meaningful than in healthcare.
So where is AI making an impact in healthcare today? What will the future bring, and how should healthcare providers and technologists get ready?
On the Season 4 premiere of GeekWire’s Health Tech Podcast, we address all of those questions with three guests: Linda Hand, CEO of Cardinal Analytx Solutions, a venture-backed company that uses predictive technology to identify people at high risk of declining health, and match them with interventions; Colt Courtright, who leads Corporate Data & Analytics at Premera Blue Cross; and Dr. David Rhew, Microsoft’s new chief medical officer and vice president of healthcare.
This episode was recorded on location at the dotBlue conference in Seattle, hosted by the returning sponsor of the show, Premera Blue Cross.
Listen above or subscribe to the GeekWire Health Tech Podcast in your favorite podcast app, and keep reading for edited highlights.
On the current state of AI in healthcare
Linda Hand, CEO, Cardinal Analytx: When I look at AI in healthcare, I see most examples in either the science of healthcare or in the practice of healthcare. I feel like it’s an emerging business for us to expand that to the insurer side of the house. Machine learning can find patterns that a human cannot, when it’s not prescribed in terms of the outcome that you’re looking for, and that’s a very powerful thing. And that’s where it can be better than a doctor.
The ability to take data and leverage that to move from a reactive care model, reactive intervention, to a proactive intervention is the promise of that because the predictions are up to 12 months in advance. And so being able to understand that someone will rise in cost eight months out is a very different opportunity for a conversation than, “Hey, I see you’re in the hospital.”
Colt Courtright, Premera Blue Cross: The healthcare industry represents $3.5 trillion a year, and annual spend is 18 percent of GDP. It’s expected to support 300 million-plus Americans. And so while some of these technological achievements are possible, you can prove out that diagnostics are in fact more accurate in some cases using machine learning versus a human being.
AI today, and over the next couple of years, is going to be more like the technology of yesterday. Think of it like a stethoscope. A stethoscope magnifies the hearing of the human doctor. It enables them to diagnose more effectively. The AI applications that I see being adopted near-term really have to do with being able to discern patterns in data, patterns in past histories that a human doctor could, if given enough time, discern on their own.
Dr. David Rhew, right, Microsoft’s new chief medical officer and vice president of healthcare, speaks on the GeekWire Health Tech Podcast next to Colt Courtright, who leads Corporate Data & Analytics at Premera Blue Cross, and Linda Hand, CEO of Cardinal Analytx, with GeekWire editor Todd Bishop far left. (GeekWire Photo / James Thorne)
David Rhew, Microsoft: Where we’re seeing the trends today are around the ability for us to start pulling in data that are cleaner, and more interoperable, that allow us to be able to then combine data sets that we couldn’t look at before. We’ve been limited in the fact that we had very dirty data sets that didn’t allow us to be able to really understand beyond what was the scope of what was currently available.
Now we have an ability to have much cleaner data sets combined with others real time. And that’s a really exciting opportunity because now we can think about how can we combine claims data with electronic health record data, with lifestyle data, with social determinants of health, and try to understand how it matches to an individual from their genomics and other types of personalizations. And that’s where the real opportunity lies.
AI’s impact on healthcare costs
Courtright: Costs are impacted by a great number of things, new drug discoveries, new medical treatments, there’s very legitimate reasons for costs to go up. However, the pricing of risks, the setting of premiums is set with the level of information we know today. And we know that machine learning creates a greater predictive accuracy in understanding future financial risk.
Rhew: There’s great opportunity for us to be able to figure out how AI will translate to lower costs. We just have to validate this on a larger scale and once we’re able to do that, then that will hopefully translate to lower costs across the board.
What AI means for doctors and patients
“I think the opportunity is really putting the human back in healthcare.” Linda Hand of Cardinal Analytx, center, speaks on the GeekWire Health Tech Podcast. (GeekWire Photo / James Thorne)
Hand: I think the opportunity is really putting the human back in healthcare. Providing insights that one can’t see even if they had enough time, putting it in front of them so that they can be very efficient in that interchange with a patient, with a member. Wherever that engagement is, I think, is a huge opportunity. You enable the human in the doctor, allow them to leverage all the insights to be the trusted adviser. People go to their primary care physician or a specialist for advice on a particular thing. Right now you feel you have to bring all the information and educate them. AI should be able to give all of that to that person so that they can actually advise and have a conversation about what is the best course of action.
Courtright: When you go to an exam room, what’s your typical view? It’s the back of your physician’s head. It’s because they are looking at their keyboard as much as they’re looking at you. And they’re doing that because of the administrative burden and the documentation requirements of medical care today. And the aggregation of that is such that doctors, clinically trained professionals, are only able to spend half of their time delivering medical care. And so when I think about the possibilities of AI over the next three to five years, I think about the opportunity to automate the basic tasks that are taking away the physicians’ attention when they deliver medical care.
Rhew: We’re talking a lot about what happens in a hospital and in a clinic. But much of healthcare is actually moving outside. It’s moving to the home, it’s moving to retail clinics. And so the user experience will be very different in those scenarios. In many cases, they will not have a doctor, a nurse, a clinical person to be able to help oversee the care, which means that the technology, the AI is going to be even more important because it’s going to allow individuals to feel confident that they can actually manage their care outside of the care of what we traditionally view as a hospital, a clinic.
Implications for data and privacy
Hand: I think we have a really inconvenient relationship with privacy. Everybody wants to keep their stuff private, but everybody wants the benefit of having the insights from using everybody else’s data. There’s just a huge disconnect there.
“Now we’re talking about the Wild West in terms of how data can be used and moved around.” Dr. David Rhew, Microsoft’s chief medical officer, speaks on the GeekWire Health Tech Podcast. (GeekWire Photo / James Thorne)
Rhew: It’s very important to be proactive on this because once the information moves outside of the medical record into the individual’s phone, it’s no longer under the context or umbrella of HIPAA. They can do what they want with that. Now we’re talking about the Wild West in terms of how data can be used and moved around. We have to really start thinking proactively about how do we put those safeguards in without being too restrictive at the same point.
Courtright: I think we are in an inflection point where we are being forced to grapple with these kinds of considerations. The Privacy and Security Standards that have governed what I would call the traditional actors in healthcare — the health plans and the providers — will remain the same. The shift is really to say the member owns their medical record. The member should be able to control that, and use it, place it where they would like it.
Future of AI in healthcare
Rhew: We will see changes in the way that people use these tools. It won’t be the same way that we practice medicine. There’ll probably be new specialties focused just on digital tools with AI. Individuals focusing more on populations rather than just on individuals themselves, or patients themselves. We will see changes. It may require that some individuals have to rethink what they used to do, but that comes along with the great benefits to the patients and the populations, the reduce costs, and improved quality.
Hand: I’m extremely optimistic. That’s why I took this job. But I will say that if we only focus on the business practice of this AI enablement and operational efficiencies, we have the ability to misuse AI to do bad things faster and at scale. AI can be used to counter that, so I hope we’re smart enough to do that, but there is a danger of that, of only focusing on one. I’d like to see us in the industry balance the science, and the practice, and the business operations to make sure that we’re looking at the right incentives across that continuum.
Courtright: I’m definitely an optimist, from the perspective of the patient, the physician, and the holders of financial risk. I think there’s a tremendous amount of opportunity in AI for those three actors, which are the dominant actors in our healthcare system. This is a target-rich environment. However you examine healthcare performance today, whether it’s preventive care, a third of it is not provided; it’s recommended chronic care, a third of it is not provided; whether it’s medical errors, and where that ranks in preventable deaths in the United States, and the cost; there’s a lot of opportunity for AI.